
基础篇[Redis]
Redis安装
首先准备一台虚拟机
当前使用centos7
centos 7 启动与切换图形界面
1 | systemctl get-default# 查看centos当前开机启动模式 |
安装Redis
如果一直显示安装失败( 可以检查一下是否是网络出现问题 )
- yum属于在线安装,及联网获取安装包,如果安装失败的话,一般和网络脱不了关系。

1.安装gcc与tcl
- Redis依赖gcc与tcl环境, 因此需要先安装gcc以及tcl
安装gcc
- 注意需要切换到root
1 | yum install gcc-c++ |
安装tcl
1 | yum install -y tcl |
2.安装并配置redis
下载redis压缩包
1 | wget https://download.redis.io/releases/redis-6.2.6.tar.gz |
解压
1 | tar -zxvf redis-6.2.6.tar.g |
把解压出来的目录移到/usr/local/bin/redis6
1 | mv redis-6.2.6 /usr/local/redis6 |
运行编译命令:
1 | make && make install |
如果没有出错,应该就安装成功了。
默认的安装路径是在 /usr/local/bin目录下:
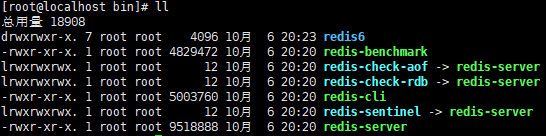
该目录以及默认配置到环境变量,因此可以在任意目录下运行这些命令。其中:
- redis-cli:是redis提供的命令行客户端
- redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本
3.启动Redis
redis的启动方式有很多种,例如:
- 默认启动
- 指定配置启动
- 开机自启
1.默认启动
1 | redis-server |
如图
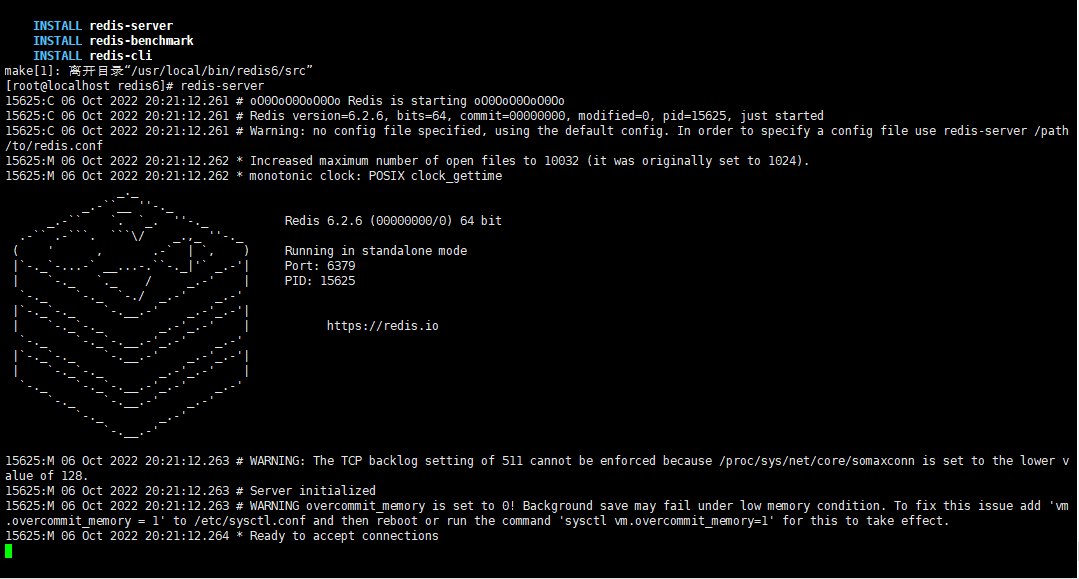
这种启动属于前台启动,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止。不推荐使用。
2.指定配置启动
如果要让Redis以后台方式启动,则必须修改Redis配置文件,就在我们之前解压的redis安装包下(/usr/local/src/redis-6.2.6),名字叫redis.conf
我们先将这个配置文件备份一份:
1 | cp redis.conf redis.conf.bck |
然后修改redis.conf文件中的一些配置:
1 | vi redi-conf |
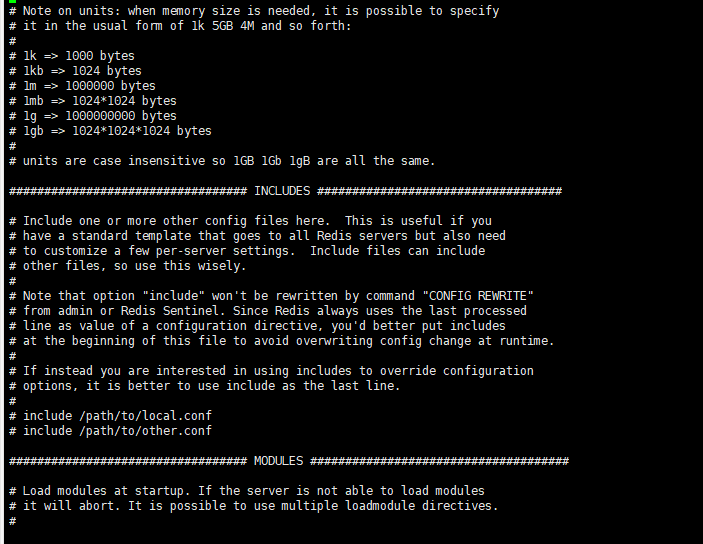
1 | # 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0 |

Redis的其它常见配置:
1 | # 监听的端口 |
关于vim编辑器
Linux vi/vim | 菜鸟教程 (runoob.com)
- 默认使用vi 命令打开文件的时候, 启动的是命令模式, 如果需要更改文件需要按下
i切换到编辑模式 - 按下
/启用搜索 - 按下
Esc退出编辑模式 - 按下
:输入wq保存并退出

启动Redis:
1 | # 进入redis安装目录 |

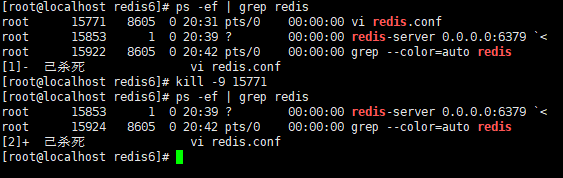
可以看到此时并没有向上一次出现页面, 说明此时Redis已经在后台运行
1 | ps -ef | grep redis |

上面的vi redis.conf 还没有关闭, 可以通过
1 | kill -9 [PID] # 杀死进程 |
停止服务:
如果不输入密码就会显示NO AUTH

1 | # 利用redis-cli来执行 shutdown 命令,即可停止 Redis 服务, |
3.开机自启
在/etc目录下新建redis目录
1 | cd /etc/ |
复制配置文件
将redis.conf文件复制到/etc/redis目录下,并重命名为6379.conf
注意redis存放的目录, 可能与我的不一样
1 | cp /usr/local/bin/redis6/redis.conf /etc/redis/6379.conf |
复制启动脚本
1 | cp /usr/local/bin/redis6/utils/redis_init_script /etc/init.d/redis |
通过查看启动脚本,确定各个路径是否正确
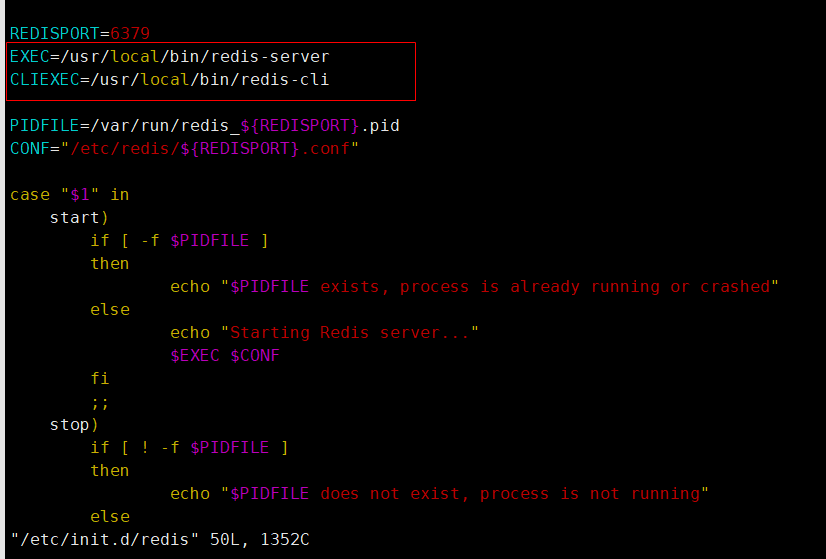
执行自启命令
1 | cd /etc/init.d/ |
如果运行结果提示:
service redisd does not support chkconfig,
解决方法: 使用vim编辑redisd文件,在第一行加入如下两行注释,保存退出,再次执行自启命令即可
# chkconfig: 2345 90 10
# description: Redis is a persistent key-value database
注释的意思是,redis服务必须在运行级2,3,4,5下被启动或关闭,启动的优先级是90,关闭的优先级是10。
启动Redis
1 | # 打开redis命令: |
如果service redis start 显示env: /etc/init.d/redis: 权限不够
那么可以chmod a+x /etc/init.d/redis ,
a+x 是给所有人加上可执行权限,包括所有者,所属组,和其他人
o+x 只是给其他人加上可执行权限
这样一来, 实践发现这个时候确实可以通过service redis start 来启动redis, 但是却无法实现redis 开机自启
chkconfig redis on 失效
1 | # chkconfig: 2345 10 90 |
4.Redis图形化客户端
应用下载 : resp-2022.2.0.0.exe https://www.aliyundrive.com/s/3tA1n4Sjv1B 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
下载安装完成后 打开
点击左上角的连接到Redis服务器按钮:
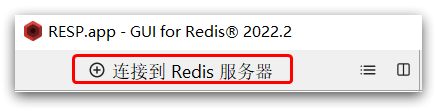
在弹出的窗口中填写Redis服务信息:
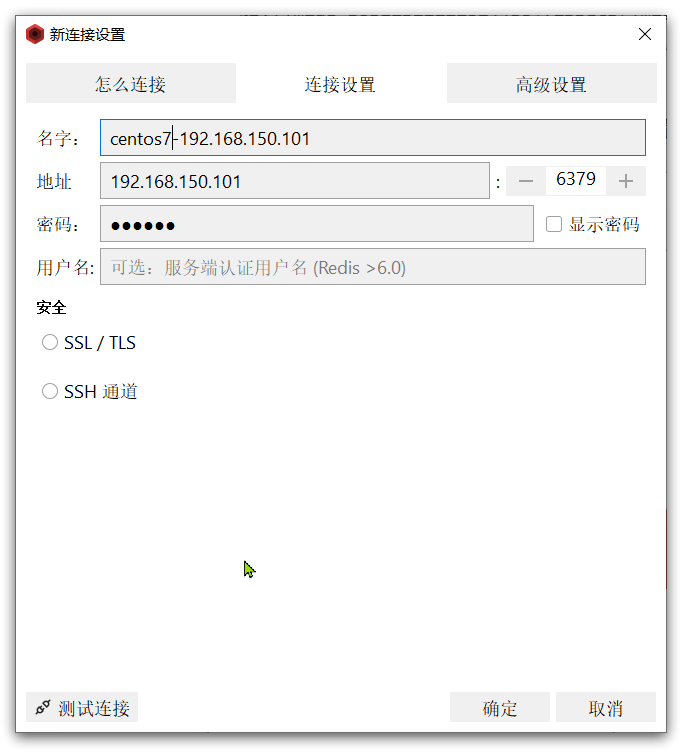
点击确定后,在左侧菜单会出现这个链接:
点击即可建立连接了。
Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库:
1 | # 选择 0号库 |
⭐遇到的一个问题
在使用图形化链接redis服务器时, 总是连接不上, 百度很长时间发现是虚拟机防火墙的原因
1 | # 禁用虚拟机防火墙 |
连接成功
Redis相关知识
- 端口6379
- 默认16个数据库,类似数组下标从0开始,初始默认使用0号库
- 使用命令select [dbid]来切换数据库。如:
select 8 - 统一密码管理,所有库同样密码。
- 使用命令select [dbid]来切换数据库。如:
- Redis是_单线程_+多路IO复用技术 (版本更新之后有多线程了,redis6)
- 多路复用是指使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)(基于操作系统的介绍)
多个客人找redis黄牛买票,redis黄牛去联系cup车站,有票就卖给redis黄牛,没票cup车站可以做其他的事情,redis黄牛和客人继续等待(描述的不是很准确大概是这样)
Redis命令
redis键(key)层级
-
keys _ 查看当前库所有key(匹配: keys _1)
-
exists key 判断某个key是否存在
-
type key 查看你的key是什么类型
-
del key 删除指定的key数据
-
unlink key 根据value选择非阻塞删除(仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作)
-
expire key 设置过期时间 单位为seconds
-
ttl key查看key还有多少时间过期(-2代表已经过期,-1表示永不过期)
-
dbsize查看当前数据库的key的数量
-
flushdb清空当前库 (清空当前的库)
举例
1
2
3
4
5
6
7
8
9
10
11
12127.0.0.1:6379[1]> select 6
OK
127.0.0.1:6379[6]> set name dhx
OK
127.0.0.1:6379[6]> set age 12
OK
127.0.0.1:6379[6]> dbsize
(integer) 2
127.0.0.1:6379[6]> FLUSHDB
OK
127.0.0.1:6379[6]> DBSIZE
(integer) 0 -
flushall通杀全部库
Key的层级结构
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如,需要存储用户.商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时如果使用id作为key,那就会冲突了,该怎么办?
我们可以通过给key添加前缀加以区分,不过这个前缀不是随便加的,有一定的规范:
Redis的key允许有多个单词形成层级结构,多个单词之间用’:'隔开,格式如下:
1 | pers:dhx:1 |
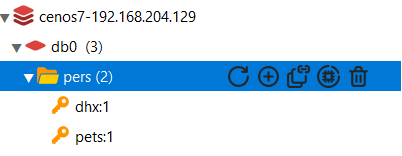
这个格式并非固定,也可以根据自己的需求来删除或添加词条。
例如我们的项目名称叫 heima,有user和product两种不同类型的数据,我们可以这样定义key:
- user相关的key:heima:user:1
- product相关的key:heima:product:1
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {“id”:1, “name”: “Jack”, “age”: 21} |
| heima:product:1 | {“id”:1, “name”: “小米11”, “price”: 4999} |
一旦我们向redis采用这样的方式存储,那么在可视化界面中,redis会以层级结构来进行存储,形成类似于这样的结构,更加方便Redis获取数据
String(Redis字符串)
string是redis最基本的类型,一个key对应一个value
string类型是二进制安全的。意味着redis的string可以包含任何数据,比如jpg图片或者序列化的对象
string类型是redis最基本的数据类型,一个redis中字符串最多可以是512M
常用命令
- set
添加键值对 - get
获取值 - append
来给当前键值对追加一个值,追加到原值的末尾 - stelen
获得值的长度 - setnx
只有在key不存在时 设置key的值 - incr
将key中储存的数字值增1,只能对数字值操作,如果为空,新增值为1 - decr
将key中储存的数字值减1,只能对数字值操作,如果为空,新增值为-1 - incrby/decrby
<步长>将key中储存的值增减,自定义步长就是加减多少。 - mset
同时设置一个或多个key-value对 - mget 同时获取一个或多个value
- msetnx
同时设置一个或多个键值对,当且仅当所有给定key都不存在 - getrange
<起始位置><结束位置> 获得值的范围,类似Java中的substring,前包,后包 - setrange
<起始位置> 用value覆写key所存储的字符串值,从<起始位置>开始(索引从0开始) - setex
<过期时间> 设置键值的用时,设置过期时间,单位秒 - getset
以新换旧,设置了新值同时获得旧值
原子性:
所谓原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何context switch(切换到另一个进程)
1、在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”(注意这里有引号),因为中断只能发生于指令之间
2、在多线程中,不能被其他进程打断的操作就叫原子操作
Redis单命令的原子性主要得益于Redis的单线程
数据结构
string的数据结构为简单动态字符串,是可以修改的字符串,内部结构实现上类似于Java的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。

如图中所示,内部为当前字符串实际分配的空间capacity 一般要高于实际字符串长度len,当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容一次只会多扩1M的空间,需要注意的是,字符串最大长度为512M
List(Redis列表)
redis列表是简单的字符串列表,按照插入顺序排序,你可以添加一个元素到列表的头部(左边)或者尾部(右边)

他的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间节点的性能会较差。
常用命令
-
LPUSH key element … :向列表左侧插入一个或多个元素
-
LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
-
RPUSH key element … :向列表右侧插入一个或多个元素
-
RPOP key:移除并返回列表右侧的第一个元素
-
LRANGE key star end:返回一段角标范围内的所有元素
-
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间 ( 阻塞 ),而不是直接返回nil
- 比如我们此时打开终端, 如果直接
BLPOP, 不设置等待的时间, 此时会直接(error) ERR wrong number of arguments for 'blpop' command - 如果我们设置等待时间为100s, 输入命令后通过图形化客户端来添加数据, 那么
BLPOP会在输入数据的瞬间执行, 同时返回等待的时间
1
2
3
4
5
6
7
8127.0.0.1:6379> BLPOP user2
(error) ERR wrong number of arguments for 'blpop' command
127.0.0.1:6379> BLPOP user2 100
1) "user2"
2) "1\n2"
(16.45s)
127.0.0.1:6379> - 比如我们此时打开终端, 如果直接
数据结构
list的数据结构为快速链表quickList
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表
他将所有的元素紧挨着一起存储,分配的是一块连续的内存
当数据量比较多的时候才会改成quicklist
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里寸的只是int类型的数据,结构上还需要两个额外的指针prev和next

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
Set(Redis集合)
redis set 对外提供的功能于list类似是一个列表的功能,特殊之处在于set是可以自动排重的,
当你需要存储一个列表数据,又不希望出现重复数据时。
set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的
redis的set是string类型的无序集合,他底层其实是一个value为null的哈希表,所以添加,删除,查找的复杂度都是O(1)
常用命令
- SADD
… 将一个或多个member元素加入到集合key中,已经存在的menmber元素将被忽略 - SMEMBERS
取出该集合的所有值 - SISMEMBER
判断集合key是否含有该value值,有1,无0 - SCARD
返回该集合的元素个数 - SREM
…删除集合中的某些元素 - SPOP
随机从该集合中吐出一个值 - SRANDMEMBER
随机从该集合中取出n个值,不会从集合中删除 - SMOVE
value把集合从一个值从一个集合移动到另一个集合 - SINTER
返回两个集合的交集元素 - SUNION
返回两个集合的并集元素 - SDIFF
返回两个集合的差集元素,1有2没有
例如两个集合:s1和s2:
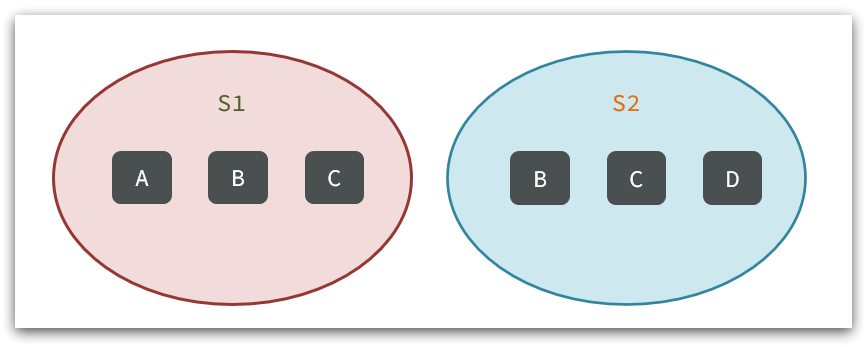
求交集:SINTER s1 s2
求s1与s2的不同:SDIFF s1 s2

具体命令
1 | 127.0.0.1:6379> sadd s1 a b c |
案例
- 将下列数据用Redis的Set集合来存储:
- 张三的好友有:李四.王五.赵六
- 李四的好友有:王五.麻子.二狗
- 利用Set的命令实现下列功能:
- 计算张三的好友有几人
- 计算张三和李四有哪些共同好友
- 查询哪些人是张三的好友却不是李四的好友
- 查询张三和李四的好友总共有哪些人
- 判断李四是否是张三的好友
- 判断张三是否是李四的好友
- 将李四从张三的好友列表中移除
1 | 127.0.0.1:6379> SADD zs lisi wangwu zhaoliu |
注意不要用汉字
- 乱码问题
1 | 127.0.0.1:6379> SADD 张三瞠 码子 |
数据结构
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
Hash(Redis哈希)
redis hash是一个键值对集合
redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象
类似Java里面的map<String,Object>
常用命令
- hset
给key集合中的field键赋值value - hget
从 集合 取出value - hmset
…批量设置hash的值 - hexists
查看哈希表key中,给定域是否存在 - hkeys
列出该hash集合的所有field - hvals
列出该hash集合的所有value - hincrby
为哈希表key中的域field的值加上增量 - hsetnx
将哈希表key中的域field的值设置为value,当且仅当域field不存在
数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则hashtable
ZSet(Redis有序集合Sorted Set)
java 中的TreeSet也是可排序集合
TreeSet底层是红黑树
redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合,不同之处是有序集合的每个成员都关联了一个score(评分、权重),这个score被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是score可以是重复的。
因为元素是有序的,所以你也可以很快的根据score或者position来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
常用命令
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF.ZINTER.ZUNION:求差集.交集.并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
- 升序获取sorted set 中的指定元素的排名:ZRANK key member
- 降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
练习
1 | 127.0.0.1:6379> ZADD stus 91 Amy 95 Jack 81 Dick |
数据结构
Sorted Set(zset)是redis提供的一个非常特别的数据结构,一方面它等价于java的数据结构Map<String,Double>,
可以给每一个元素value赋予一个权值score,另一方面又类似于TreeSet,内部的元素会按照权重score进行排序,
可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
1、hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
2、跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
**跳跃表 **
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。
Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳跃表
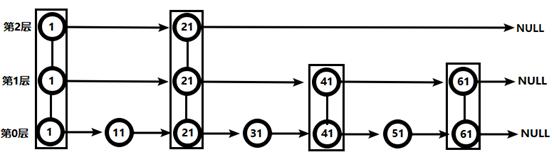
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
(我自己的理解就是跳一个进行比较,比目标值小就又跳一个比较,比目标值大就比较前一个值。)
从此可以看出跳跃表比有序链表效率要高
Redis的Java客户端-Jedis
在Redis官网中提供了各种语言的客户端,地址:https://redis.io/docs/clients/

其中Java客户端也包含很多:
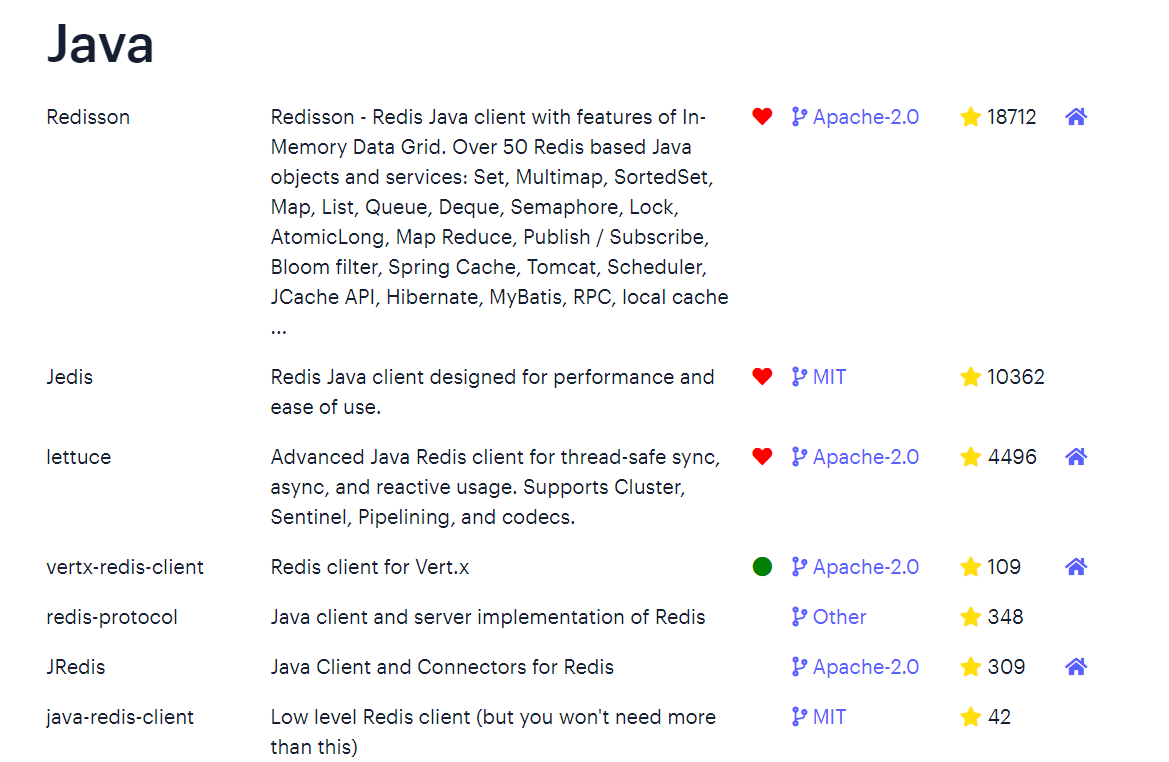
标记为❤的就是推荐使用的java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了Redis命令对应的API,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装,因此我们后期会直接以SpringDataRedis来学习。
- Redisson:是在Redis基础上实现了分布式的可伸缩的java数据结构,例如Map.Queue等,而且支持跨进程的同步机制:Lock.Semaphore等待,比较适合用来实现特殊的功能需求。
1 Jedis快速入门
入门案例详细步骤
案例分析:
0)创建工程:

1)引入依赖:
1 | <!--jedis--> |
2)建立连接
新建一个单元测试类,内容如下:
1 | private Jedis jedis; |
3)测试:
1 |
|
4)释放资源
1 |
|
2 Jedis连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此我们推荐大家使用Jedis连接池代替Jedis的直连方式
有关池化思想,并不仅仅是这里会使用,很多地方都有,比如说我们的数据库连接池,比如我们tomcat中的线程池,这些都是池化思想的体现。
2.1.创建Jedis的连接池
1 | package pers.dhx_.jedis; |
那么就可以更改之前的@BeforeEach
1 |
|
代码说明:
-
1) JedisConnectionFacotry:工厂设计模式是实际开发中非常常用的一种设计模式,我们可以使用工厂,去降低代的耦合,比如Spring中的Bean的创建,就用到了工厂设计模式
-
2)静态代码块:随着类的加载而加载,确保只能执行一次,我们在加载当前工厂类的时候,就可以执行static的操作完成对 连接池的初始化
-
3)最后提供返回连接池中连接的方法.
2.2.改造原始代码
代码说明:
1.在我们完成了使用工厂设计模式来完成代码的编写之后,我们在获得连接时,就可以通过工厂来获得。
,而不用直接去new对象,降低耦合,并且使用的还是连接池对象。
2.当我们使用了连接池后,当我们关闭连接其实并不是关闭,而是将Jedis还回连接池的。
1 |
|
Jedis.java
可以看到底层实现的close() 如果是使用连接池, 那么实际上是吧链接归还到连接池中, 并不会真正的销毁
1 | public void close() { |
Redis的Java客户端-SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis,官网地址:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK.JSON.字符串.Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

1.快速使用
SpringBoot已经提供了对SpringDataRedis的支持,使用非常简单:
1.1.导入pom坐标
🔥注意, springboot在项目初始化的时候没有为我们引入
commons-pool2的依赖, 需要手动添加
1 |
|
1.2 .配置文件
1 | spring: |
1.3.测试代码
1 |
|
提示:SpringDataJpa使用起来非常简单,记住如下几个步骤即可
SpringDataRedis的使用步骤:
- 引入spring-boot-starter-data-redis依赖
- 在application.yml配置Redis信息
- 注入RedisTemplate
2 .数据序列化器
RedisTemplate可以接收任意Object作为值写入Redis:
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:
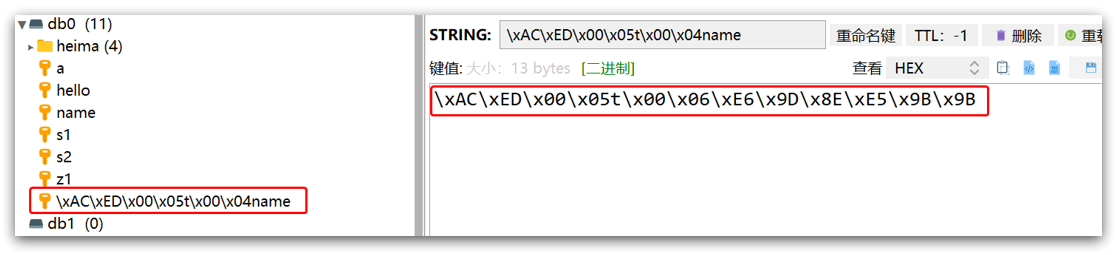
缺点:
- 可读性差
- 内存占用较大
我们可以自定义RedisTemplate的序列化方式,代码如下:
1 |
|
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:
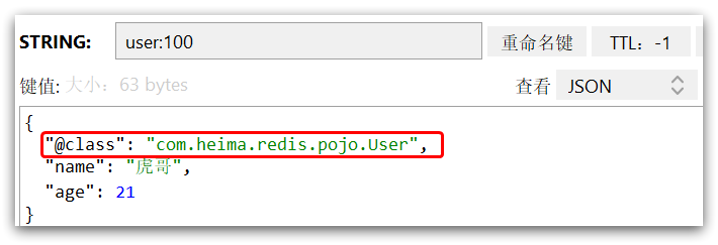
整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象。不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
执行代码
1 |
|
写入成功

测试保存JSON字符串
1 |
|
可以看到User在传输的过程中完成了序列化以及反序列化


3 StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图:

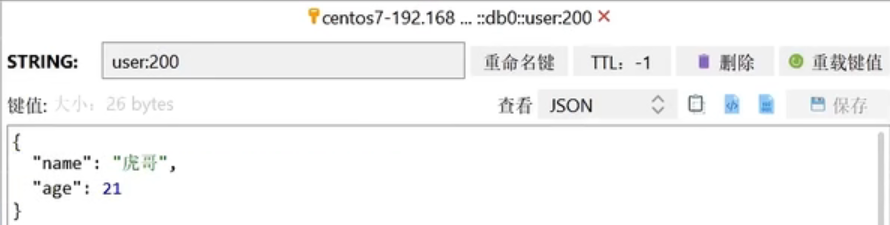
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样,在存储value时,我们就不需要在内存中就不用多存储数据,从而节约我们的内存空间
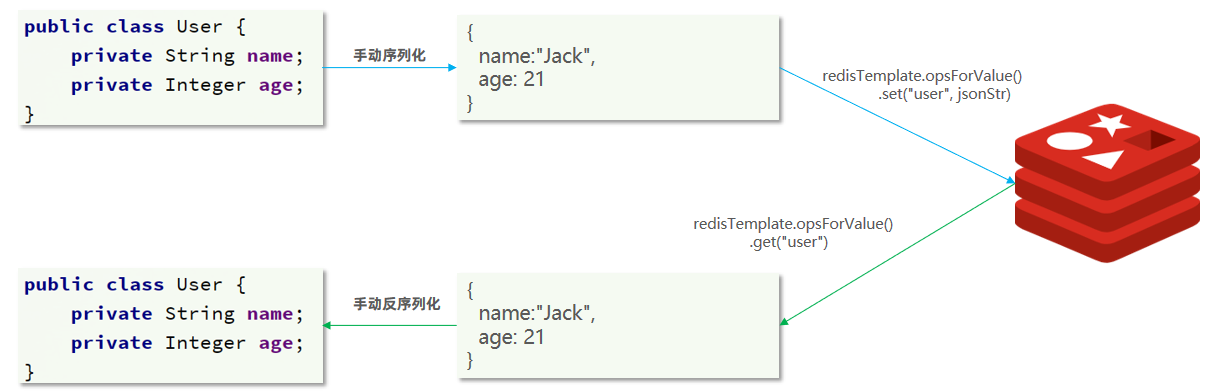
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式。
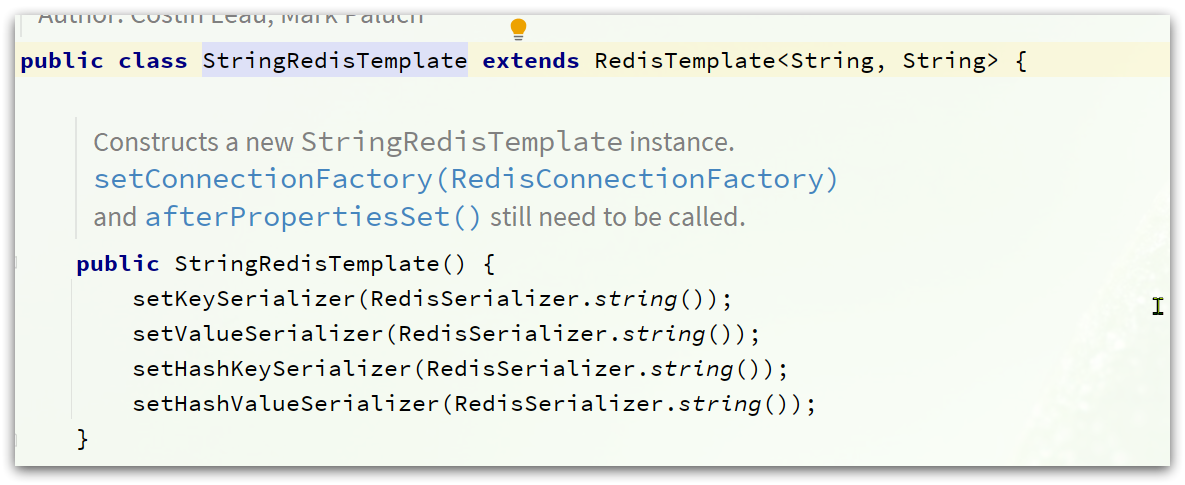
省去了我们自定义RedisTemplate的序列化方式的步骤,而是直接使用:
1 |
|
此时我们再来看一看存储的数据,小伙伴们就会发现那个class数据已经不在了,节约了我们的空间~
最后小总结:
RedisTemplate的两种序列化实践方案:
-
方案一:
- 自定义RedisTemplate
- 修改RedisTemplate的序列化器为GenericJackson2JsonRedisSerializer
-
方案二:
- 使用StringRedisTemplate
- 写入Redis时,手动把对象序列化为JSON
- 读取Redis时,手动把读取到的JSON反序列化为对象
4 Hash结构操作
简单操作
1 |
|









